Тематическое моделирование¶
Запуск новой задачи тематического моделирования¶
WebTopicMiner поддерживает два алгоритма тематического моделирования: сэмплирование Гиббса и BigARTM.
Для того, чтобы запустить моделирование, предназначена кнопка «Run topic modeling», находящаяся в меню
действий для tmlda файлов на вкладке «Workspace».

Нажав на эту кнопку вы попадаете в интерфейс настроек моделирования.
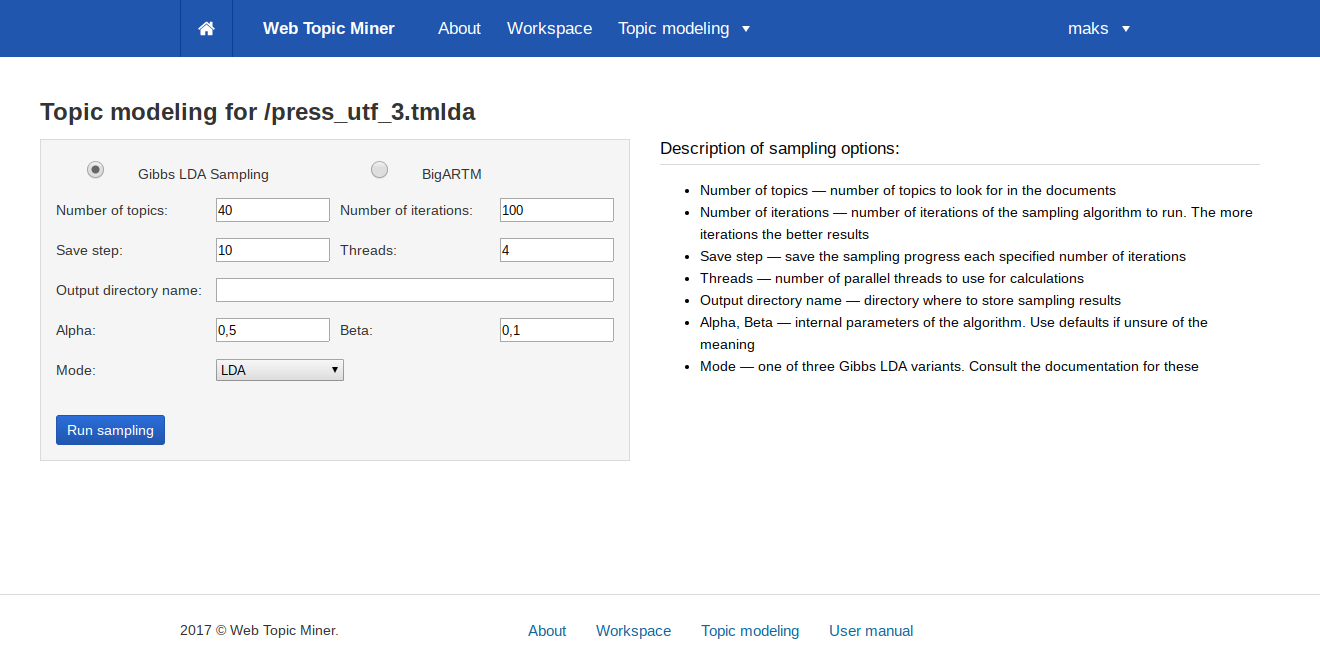
На этой странице доступен выбор алгоритма: переключатель «Gibbs LDA Sampling» и «BigARTM».
Моделирование с помощью сэмплирования Гиббса¶
В этом алгоритме для настройки доступны следующие параметры:
- «Alpha», «Beta» — коэффициенты, определяющие поведения алгоритма сэмплирования. Рекомендуется использовать значения по умолчанию
- «Number of topics» — число тем, для которых будет проводиться моделирование
- «Number of iterations» — число итераций алгоритма сэмплирования
- «Save step» — число итераций, по истечении которых текущий результат будет сохраняться и отображаться на этой странице. Не рекомендуется использовать маленькие значения, так как частое сохранение результатов замедляет работу моделирования
- «OpenMP threads» — число параллельных потоков, используемых для моделирования. Рекомендуются значения 4 или 8
- «Output directory name» — название каталога, в который будут сохранены результаты моделирования. Этот каталог появится среди ваших файлов на вкладке «Workspace»
Параметр «Mode» задаёт тип тематической модели. WebTopicMiner поддерживает три типа:
- «LDA» — стандартная модель
- «Supervised LDA» — модель, позволяющая фиксировать начальные темы для нескольких слов
- «Granulated LDA» — гранулированное сэмплирование, учитывающие несколько соседних слов
В режиме «ISLDA» доступна форма ввода фиксированной темы:

Каждому слову можно назначить до 5 тем в полях «Topic 1», …, «Topic 5», нумерация тем начинается с 1.
Поле ввода слова будет автоматически предлагать слова, встречающиеся в TMLDA файле:
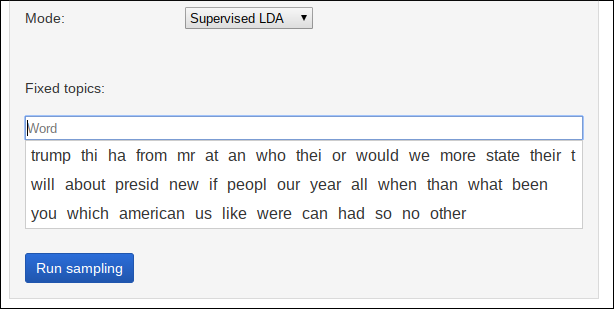
Для того, чтобы запомнить слово, нажмите кнопку «Add».
В режиме «GLDA» доступна поле выбора размера окна:
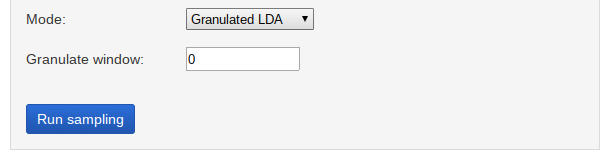
После ввода всех параметров нажмите на кнопку «Run sampling». После этого все поля ввода станут неактивными, а внизу страницы будет отображаться текущий статус и результаты сэмплирования.

Моделирование с помощью BigARTM¶

В режиме BigARTM опции «Number of topics», «Number of iterations», «Savestep», «Threads» и «Output directory name» имеют тот же смысл, что и для сэмплирования Гиббса. Кроме этого доступны следующие опции:
- «BigARTM text options» — дополнительные параметры регулизаторов BigARTM, передаваемые в библиотеку. Может быть пустым.
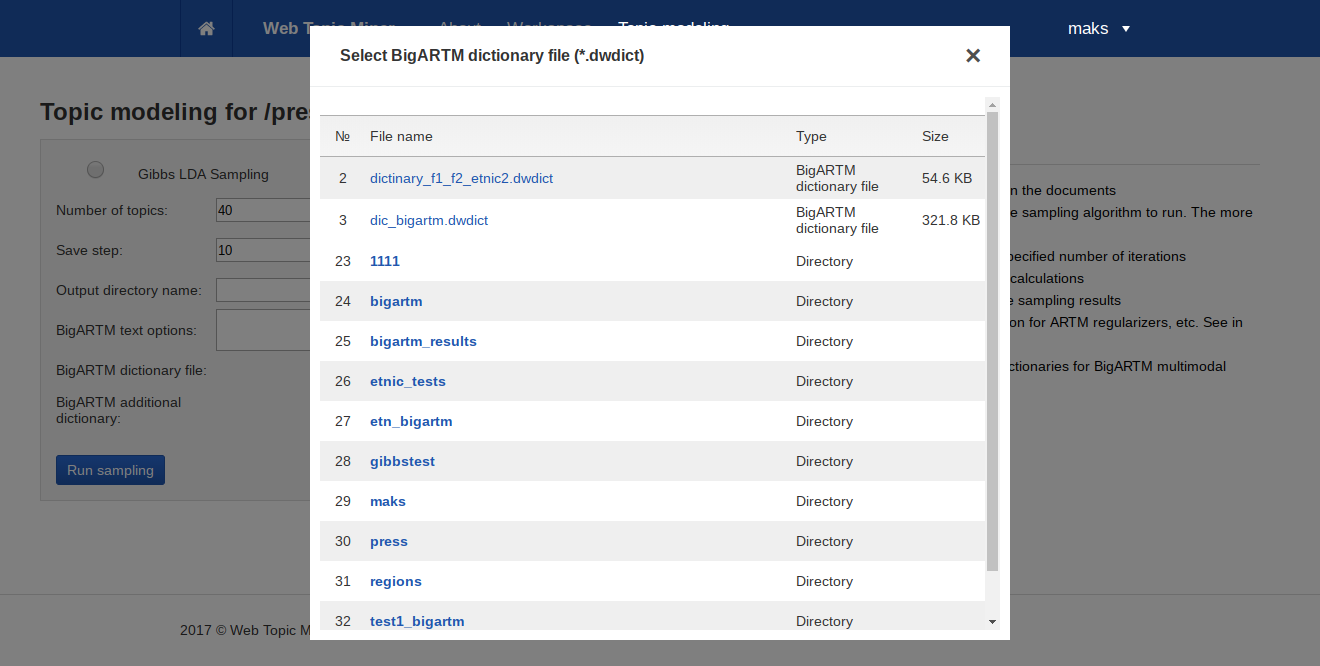
- «BigARTM dictionary file» — обязательный параметр. Файл со словарем для дополнительных модальностей BigARTM, полученный с помощью TopicMiner.
- «BigARTM additional dictionary» — текстовый файл в кодировке UTF-8, содержащий дополнительный словарь для BigARTM, например словарь этнонимов. Каждое слово должно находиться на отдельной строке.
Выбрать файловые параметры можно с помощью кнопки «Browse», которая отображает все подходящие файлы, которые вы загрузили на сервер.
Просмотр выполняющихся и завершенных задач моделирования¶
Все задачи, которые выполняются на сервере в текущий момент, представлены в выпадающем меню вкладки «Topic modeling»:

Каждая задача представлена названием своего tmlda файла. Ссылка «View finished topic modeling tasks» открывает
таблицу, содержащие все завершённые задачи.

Здесь кроме имени файла указано число итераций, число тем и время создания задачи, для упрощения поиска нужной задачи среди большого числа похожих.
Нажатие на имя файла ведёт на страницу результатов тематического моделирования.
Просмотр результатов¶
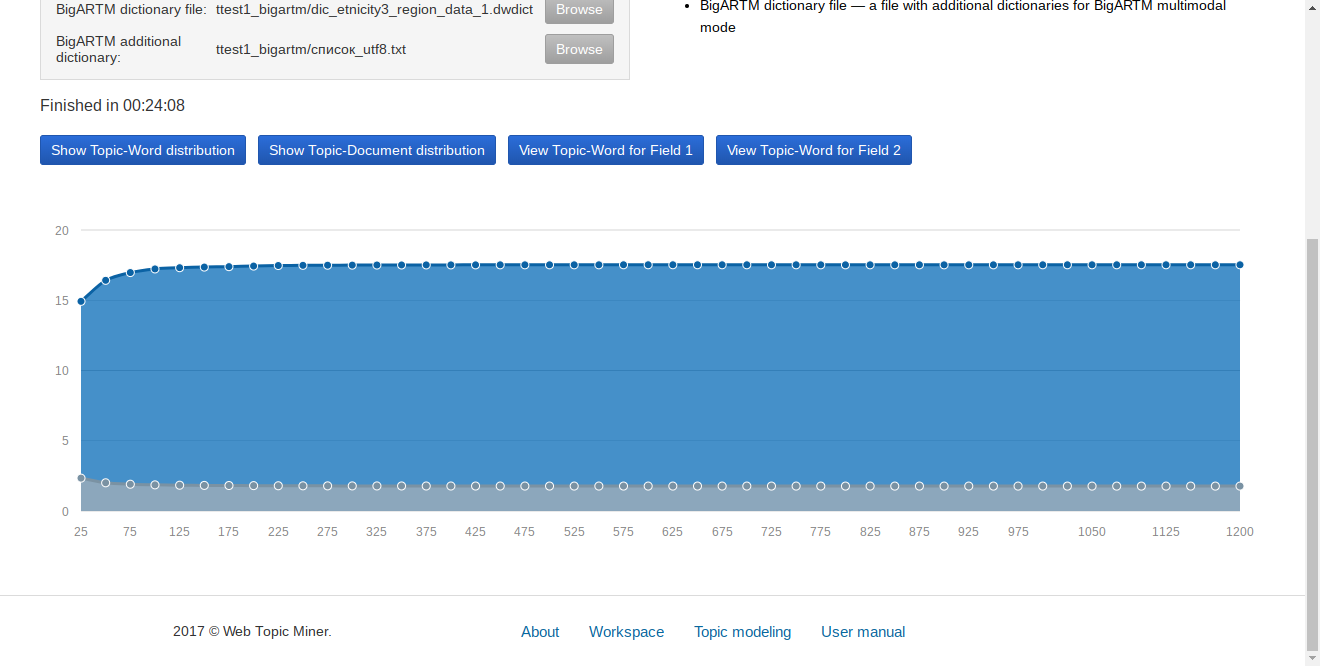
Страница результатов содержит обзор параметров, с которыми запускалось моделирование. Внизу страницы находится график, показывающий сходимость процесса. Синий и серый график показывают соответственно процент документов и слов во всех темах, вероятности которых выше средней. В конце процесса моделирование этот процент не должен сильно менятся от итерации к итерации.

Над графиком находятся две кнопки, позволяющие просмотреть распределение слов и документов по темам.
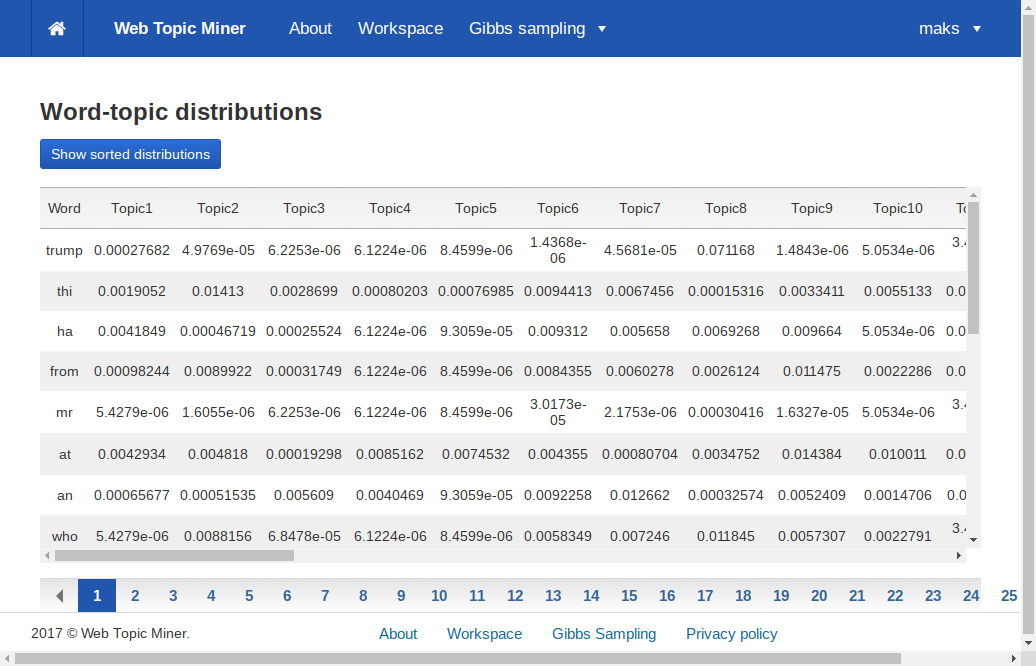
В матрице слова-темы для каждого слова указана вероятность принадлежности этого слова каждой теме.
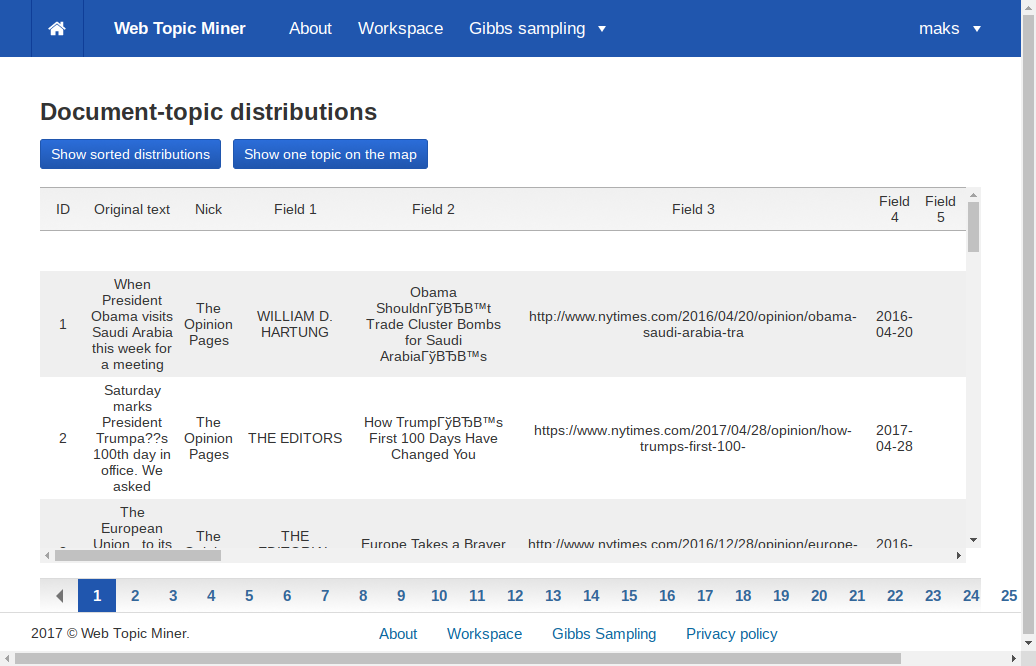
В матрице документы-темы для каждого документа также указана вероятность принадлежности темам. При нажатии на строку открывается всплывающее окно, содержащие полный текст выбранного документа. Дополнительно в этой матрице представлены метаданные каждого документа в файле.
Обе матрицы можно отсортировать для удобства чтения. При этом сортированная матрица слова-темы для каждой темы будет содержать ячейку вида «слово: вероятность». Слова в каждом столбце упорядочены по убыванию вероятности.

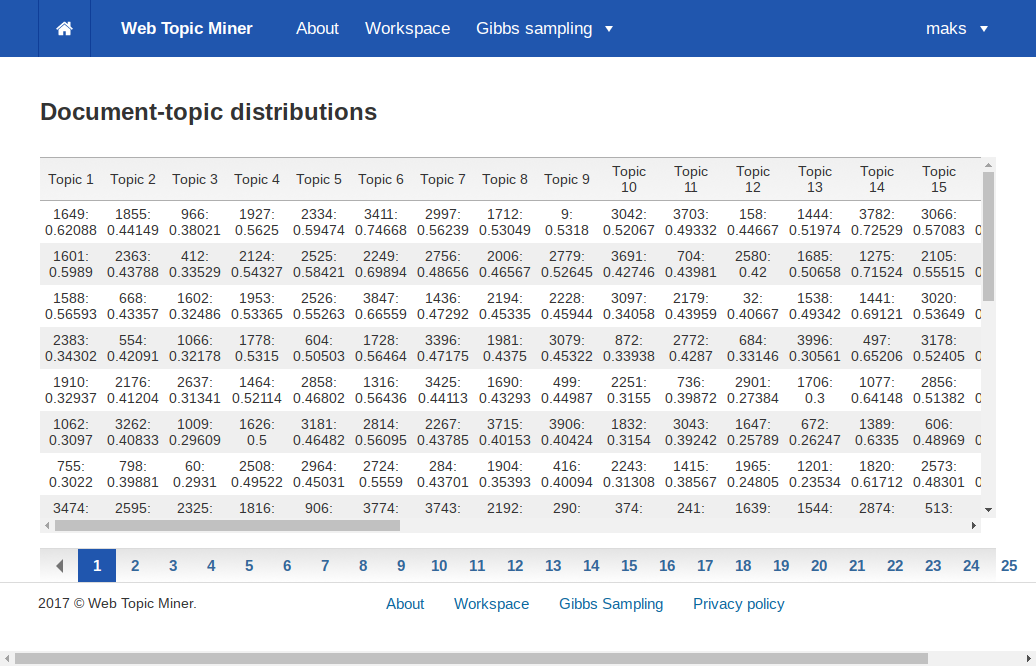
В сортированной матрице документы-темы аналогично содержатся упорядоченные ячейки вида «id документа: вероятность». При нажатии на каждую ячейку открывается полный текст указанного в ней документа.

Для задач в режиме BigARTM также доступны дополнительные кнопки, показывающие распределения тем для всех дополнительных модальностей.
С этими матрицами можно производить те же действия, что и с обычной матрицей Word-Topic.
Сентимент-анализ тем¶
Для документов на русском языке доступно проведение сентимент-анализа тем. Для этого предназначена кнопка «Add sentiment data for words in each topic», размещённая на странице отсортированной матрицы слова-темы.
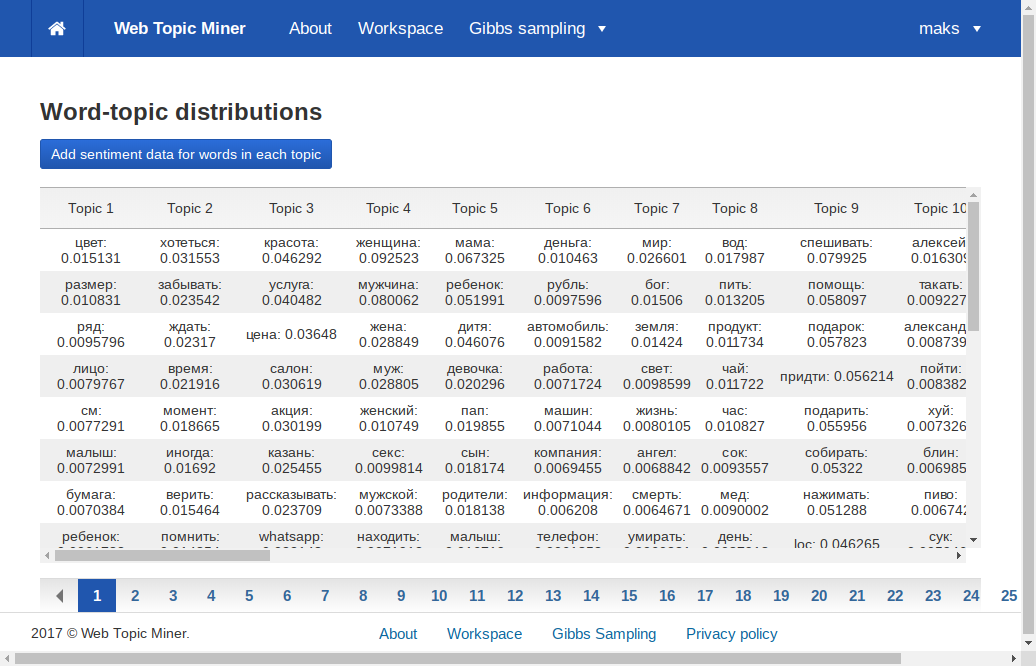
При нажатии на эту кнопку можно выбрать, какое количество самых вероятных слов в каждой теме учитывать. После того, как процесс будет закончен, в каждую ячейку кроме слова и его вероятности добавится новое число — сентиментная оценка слова по шкале от -2 до 2. Для удобства анализа положительные слова окрашены в зелёный цвет, а отрицательные — в красный. Нейтральные слова цвета не имеют.

На данный момент WebTopicMiner использует встроенный сентимент-словарь для русского языка, разработанный в Лаборатории Интернет-Исследований.
Отображение распределения темы на карте России¶
Если какой-то из столбцов метаданных документа содержит названия субъекта Российской Федерации, к которому относится документ, возможно отобразить распределение произвольной темы на карте России. Для этого предназначена кнопка «Show one topic on the map», при нажатии на которую открывается форма выбора темы.
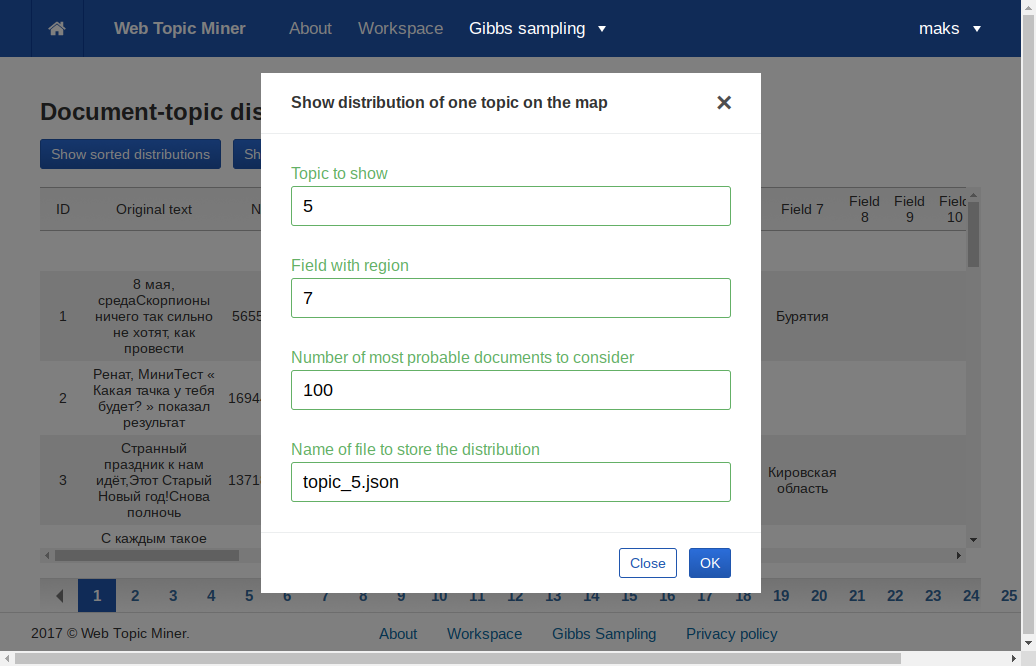
Выберите номер темы, которую требуется отобразить, номер поля метаданных, в котором содержится регион, и число самых
вероятных документов темы, которые требуется учитывать. В последнем поле укажите имя json-файла, в которой будет
сохранён результат. После нажатия на «Ok» вы будете перенаправлены в каталог, указанный как «Output directory» для
задачи сэмплирования. Через небольшое время в этом каталоге появится json-файл с указанным вами названием.
Для того, чтобы посмотреть карту, нажмите на ссылку «View on map» в меню действий этого файла. Откроется карта России, на которую нанесены контуры регионов.

Регионы, в которых выбранной темы нет, отображены только контуром. Остальные регионы окрашены по цветовой шкале от синего до оранжевого в зависимости от доли темы в этом регионе.
При нажатии на регион показывается его название и процент темы.
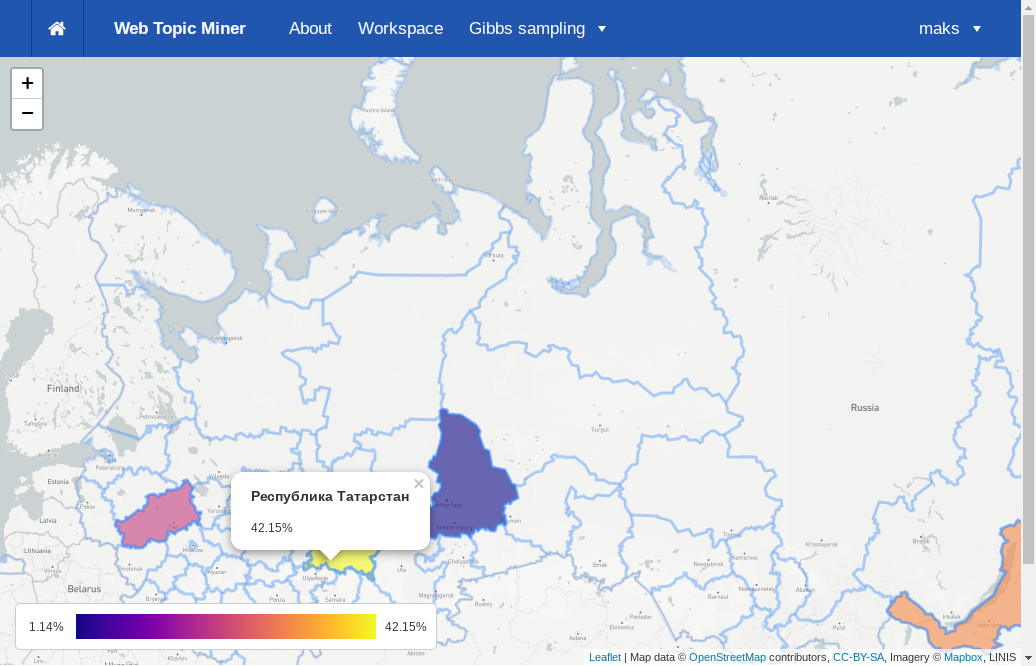
В левом нижнем углу карты находится индикатор цветовой шкалы, который показывает, в каких пределах находятся вероятности тем и каким им соответствуют цвета. Нажав на индикатор, можно изменить цветовую шкалу на любую из встроенных.
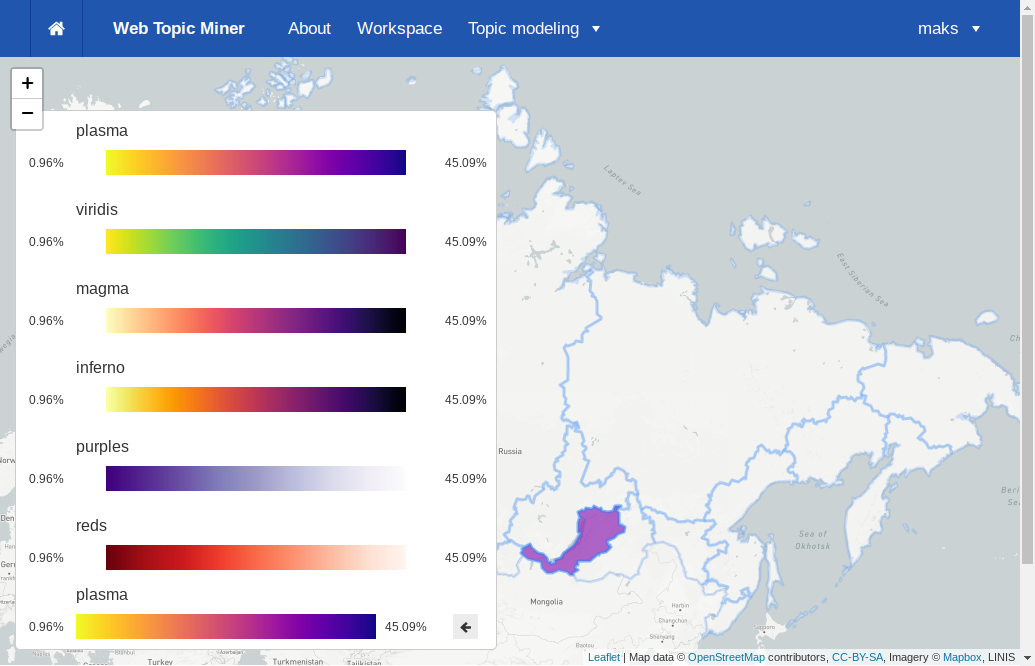
Кнопка со стрелкой позволяет инвертировать направление цветовой шкалы (от темного к светлому и наоборот).
Просмотр распределения тем во времени¶
Если какое-то поле метаданных файла TMLDA содержит дату написания документа в формате «ДД.ММ.ГГГГ», то можно построить график распределения вероятности выбранной темы во времени.
Для этого надо нажать кнопку «Plot topic probabilities per time interval» на странице матрицы Topic-Document или дополнительной матрицы BigARTM для поля, содержащего дату. В открывающемся диалоге можно указать номер поля с датой, интересующий топик, интервал дат (месяц или неделя) и количество самых вероятных документов в теме, которые требуется рассмотреть.
После ввода всех параметров график будет отображён в нижней части той же страницы.

По горизонтальной оси отложены первые даты выбранного периода (понедельник каждой недели или первое число каждого месяца), по вертикальной — суммарная вероятность (в процентах) документов, написанных в этот период. Вероятности нормализованы так, чтобы сумма по всем периодам равнялась 100%.